
Artist in Residence

Visual Artist & Designer
Finding all flights to Rome was quite a hassle - here's what the team thinks you should know about how this dataviz project came about. From tools to design decisions and technical challenges.
Intro
Hi, I am Stephan,
I was part of moovel lab for Flights to Rome (and What the Street?!) and am happy to guide you through the creation process of the project’s main imagery.
I am a designer, but also wrote much of the code for the visualisations (as always along with the whole team).
Flights to Rome is our follow-up to Roads to Rome which was dealing with the the age old saying that "all roads lead to Rome". We verified this for Europe [and USA], but could never do so on a global scale, due to the severe lack of roads across the world’s oceans.
Flights to Rome was born out of the curiosity of a true global image:
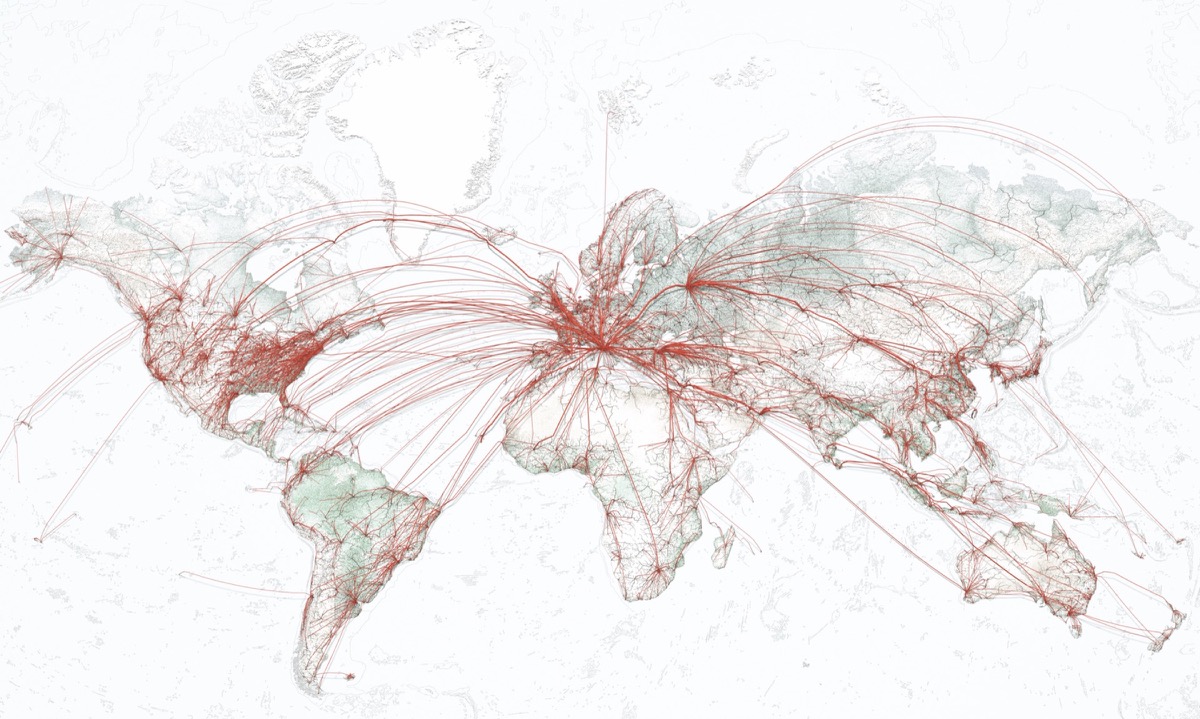
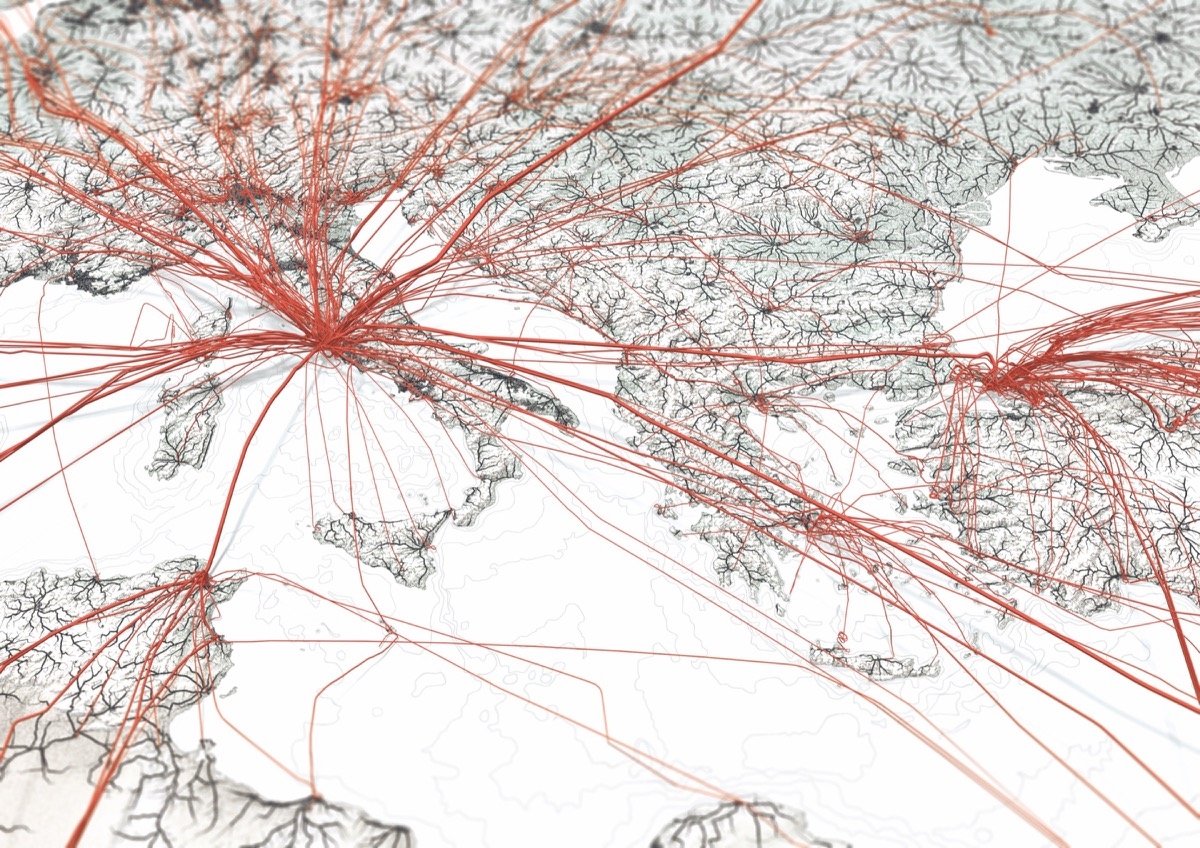
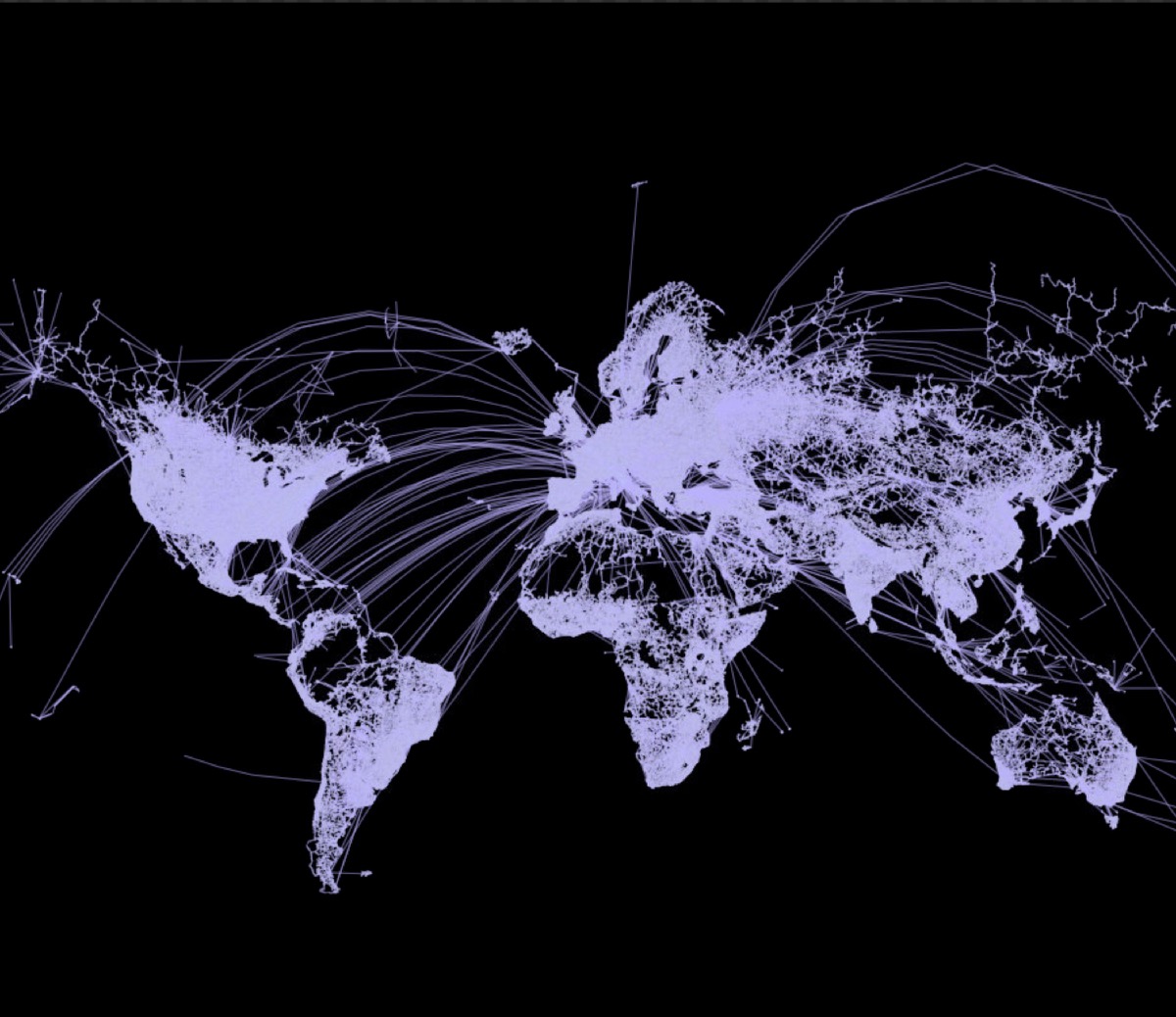
One of the project’s final images
712.425 People driving & flying to the airport [black lines] and hop on a plane to go to Rome [red lines]. The underlying base layer shows the general topography and in addition: elevation in Cross-blended Hypsometric tints [shaded green], bathymetry [blue underwater contour line] and urban areas [dark grey areas around cities].
Overview
To create this global image of Flights to Rome we had to tackle three big questions:
- What data do we need to make this happen?
- How do we simulate people’s journeys?
- How can we make this much data readable?
Disclaimer: This blog post will appear more linear than the actual process was. There was lots of trial and error involved. Also bear with me - it's a bit of a long read.
1. Data
Roads to Rome was great because the highlighted roads in itself contained a lot of information:
You could see coastlines, country borders, mountains just by looking at how people drive to Rome. A detailed basemap wasn’t even necessary to convey this information.
We expected the same thing to happen with flights – major airports, blocked airways or common flight paths would be ready to be discovered by the observer.
1.1. Roads in the sky
Roads are the car’s infrastructure, so what is a plane’s infrastructure? There are no roads, but the sky has its limits: laws of nature and laws of people.
The higher you go, the more efficient you travel, but how low you go and where you go is limited by laws – how this influences air traffic can only be shows by having real flight trajectories.
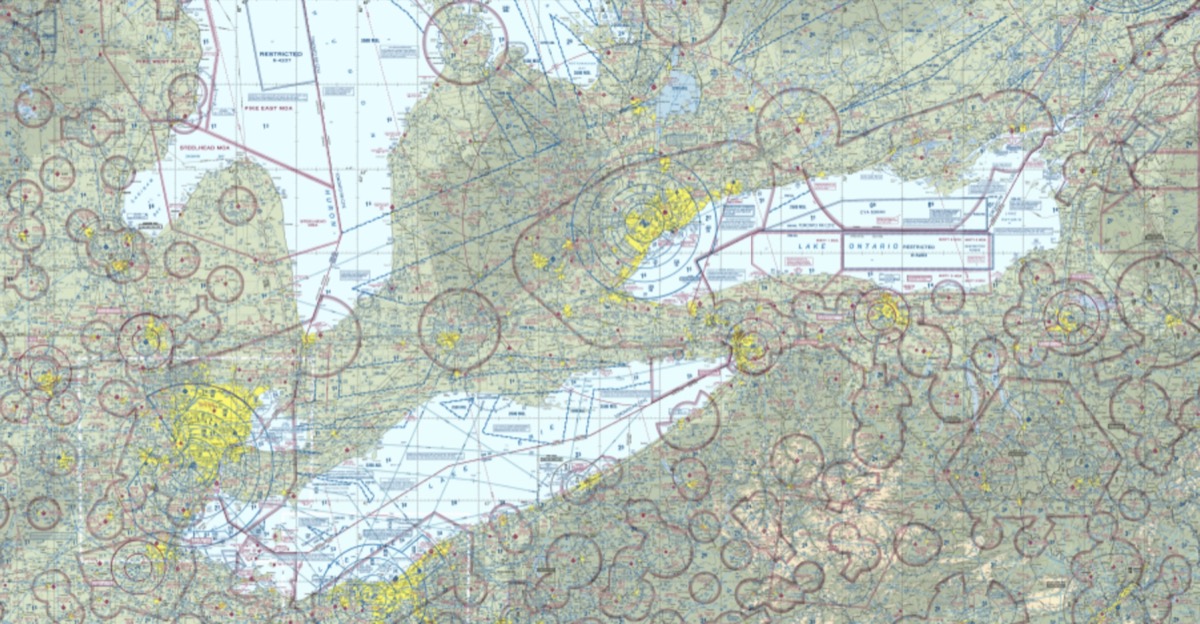
Aviation charts
Aviation charts highlight areas with airspace regulations iflightplanner https://www.iflightplanner.com/AviationCharts/
Digging for data
The problem is, that publicly accessible datasets are incomplete. There is for example ADS-B Exchange which contains trajectories, but not for the whole world. Then there is the OpenFlights dataset, which is global, but contains only departure and arrival airport. (The latter however turned out to be a great choice for prototyping)
Therefore we searched for a partner which could provide the data we needed. We found a one in Flightradar24. They are a global flight tracking service that provides real-time information. Ever wondered where the plane of your loved one is? Flightradar24 has the answer for you.
They were thrilled by the project idea which we illustrated with some early sketches:
Learning to fly, with no wings.
First drafts with fake data showing Flights to Berlin; Flights to the Flightradar24 headquarter in Stockholm, Sweden
A few calls later both us were convinced, that it was a good idea to let us peek into their data.
Getting to know my friend the data
If you have never worked with data, it’s like a grand scale version of somebody handing you a thick folder and telling you to just search for what you need.
Sometimes data is standardised … but mostly not (which means additional work is needed).
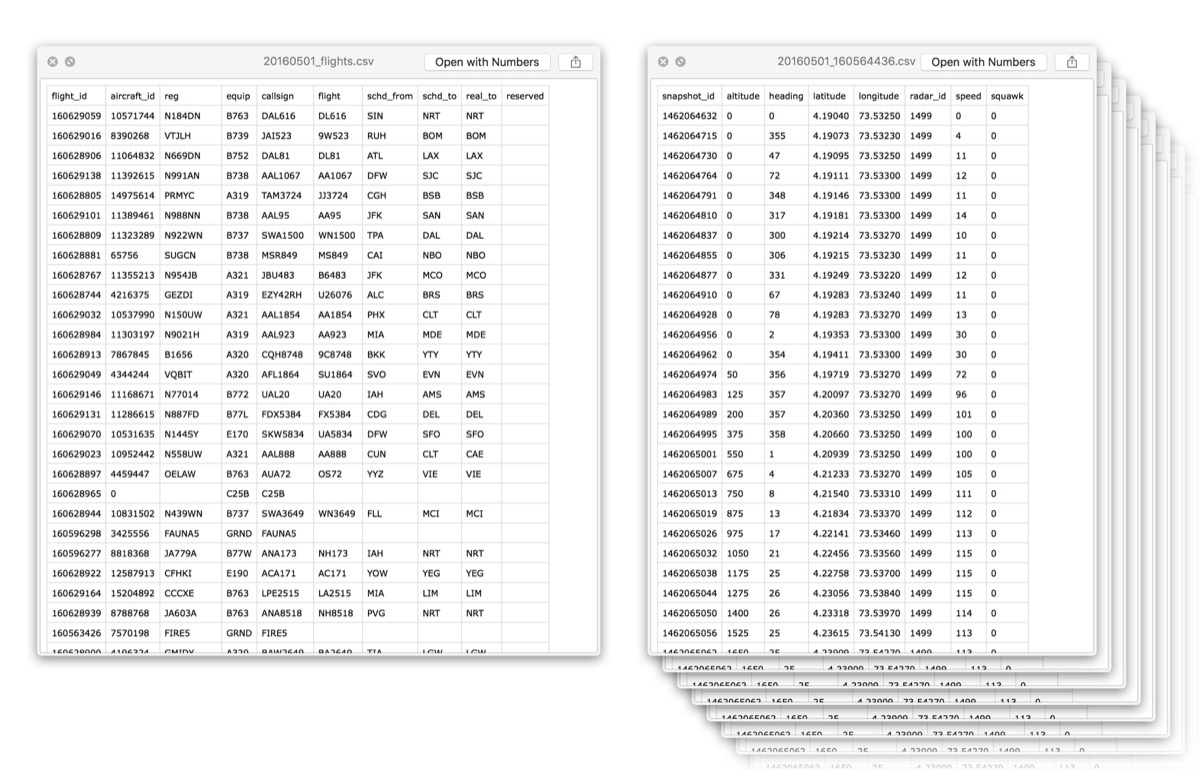
Data. Data everywhere.
left: An overview file of where flights travelled to and from. right: Some of thousands and thousands of files telling us the exact trajectory.
Visualising is understanding
Data is nothing intuitive, just a bunch of words, numbers and weird codes. Visualising is therefore necessary to understand what is going on. So we wrote a script which processes the many many files we received and converts the data into something we can look at (a geojson).
The result after processing all files to single big file, as seen in QGIS (without any styling applied):
Getting a first overview.
QGIS is a handy open source tool [Geographical Information System] for inspecting large geospatial datasets. It’s not that great for final styling, but if you just want to have a first look, it is amazing.
What does this image tell us:
- We don’t see any recorded flight to Antarctica – bummer.
- There is definitely a concentration of flights (and therefore airports) in Europe and North America.
- Otherwise – unshockingly – the dark areas match with population density pretty well.
- We can clearly make out small islands.
- It looks surprisingly clean above the sea and deserts (no turns or anything). This is due to the reason that no data is gathered in those areas. (Note: A straight line on a globe results in a curved line on a map, due to how maps are created)
Other than that we can’t see much else which is fine for now. Depending on which insight you think might be hidden somewhere, you have to create a different visualisation for it. → Personal Learnings: Debugging as Inspiration
In general, the data looks great, so we can continue with our journey.
Extract flight routes
As you might expect a lot of flights travel between the same destination – e.g. the most frequently trafficked flight route is Jeju to Seoul in Korea with 848 flights in one week!
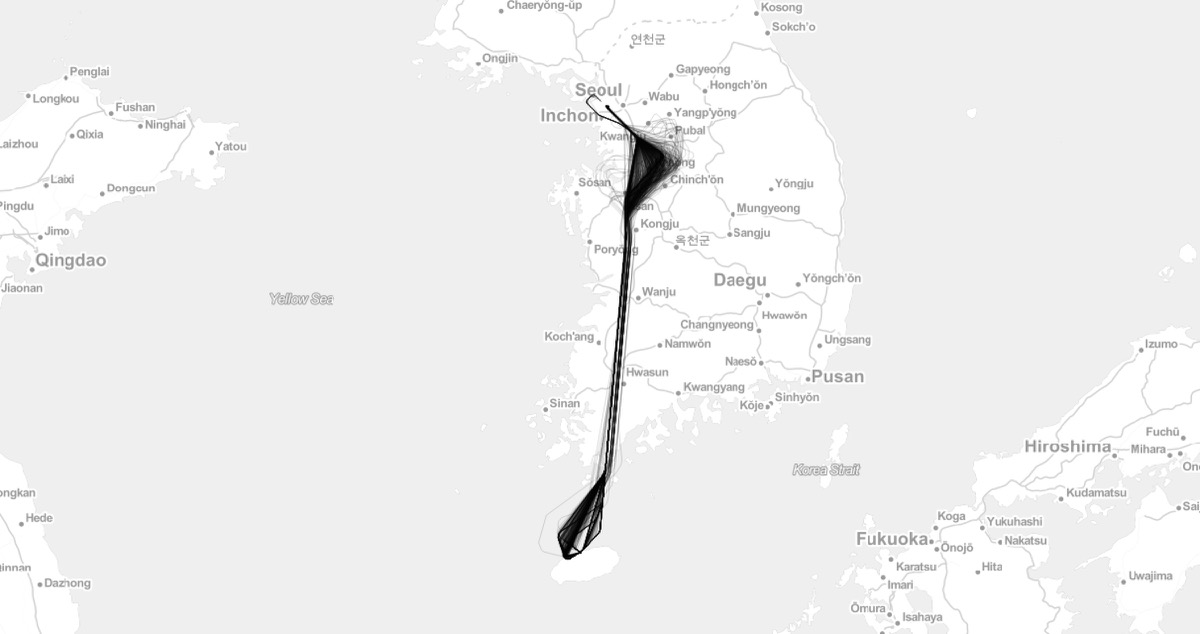
Learning about flights: The most busy route in our set.
All flights from Jeju International Airport to Gimpo International Airport in Korea
We wanted to find these common flight routes in our data. To us, a flight route is like a highway – you might switch lanes, but essentially this is the way you travel long distances.
Extracting routes was easy, because airports have a standardised three letter abbreviation called IATA which you know from flying (e.g. SFO for San Francisco Airport or TXL for Berlin Tegel Airport).
So we save every flight route with the same schema (AAA-BBB, where AAA is the departure airport and BBB the arrival airport), which we then group by that. Et voilá, we have all flight routes (in total 52680).
Sidenote: At this point we also switched to loading data into a database (mongoDB in our case), because (among other things) you can run analysis easily and it is faster to process than plain files.
Did you read me?
You might have noticed that I used the words, corridor, trajectory and route. They all talk about a line across the sky, but in a slightly different way. In a project, where it is the case that different things are easy to mistake, it makes sense to create your own definitions:
- Flight: One single flight, no matter where to, where from, etc.
- Route: From which to which airport is the plane going (e.g. SFO–TLX)
- Trajectory: The exact coordinates how a plane travelled
- Corridor: The most commonly taken trajectory
Things we didn’t name, but should have:
- Link between roads and airports
- Airports which are not connected to the road network
- Flights that have an intermediate stop which is not tagged in the data
The most common flight
When you drive you have no choice but taking the road – there is always one recommended route. This route changes depending on traffic, weather, etc. – as do air routes.
In Roads to Rome we chose to use the route which is most likely under normal circumstances. We wanted to do the same with flights, so we had to find out which trajectory pilots most commonly take for each route.
We ended up writing our own algorithm for this problem:
Making a Corridor
We can see that the image is much clearer to read. Europe is very tightly connected, but if we wander more to the east the sky’s “highways” are obvious.
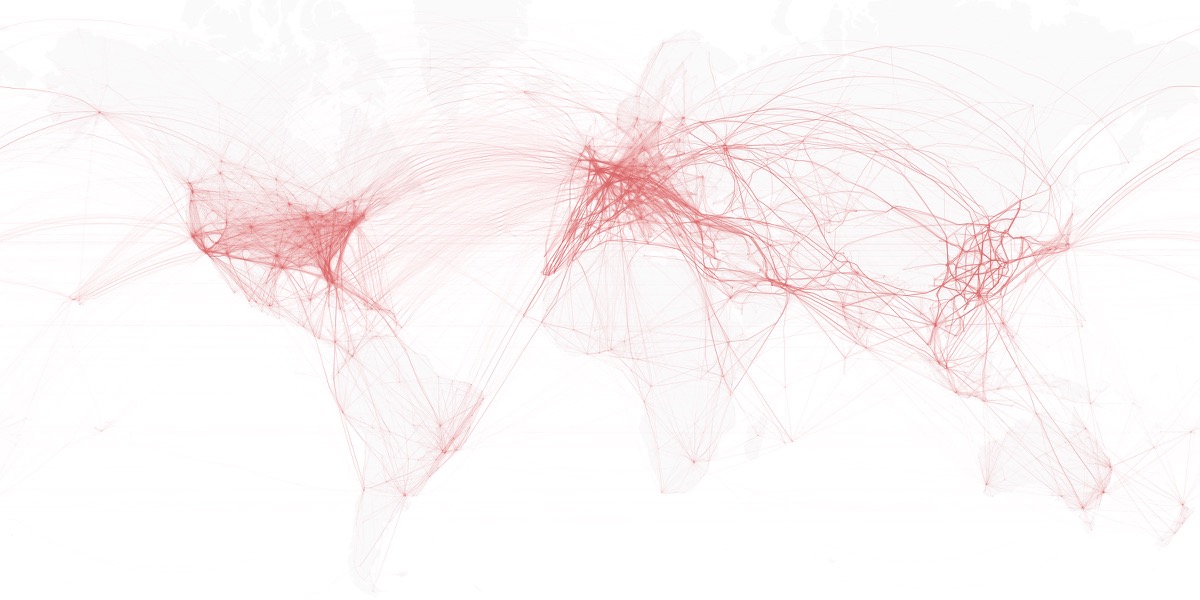
Applying this technique to all routes results in this
Each flight route rendered with its “corridor”
1.2. Downloading 65 gb of Earth
The image above shows already clearly what we had in mind with flights, but remember, we wanted to get to Rome from all possible places on earth – People’s journeys start at home, not the airport.
So after working to get the data for the sky, we had to get the data on ground level. This is the same process, which we had to do for Roads to Rome, but it is important to understand for some of the challenges later down the project’s road.
There is OpenStreetMap [OSM]. OSM is like Wikipedia for maps – people all over the world enter streets, buildings, bridges, etc., thus creating a detailed global map which can be freely downloaded and used by anyone. (Shoutout to GeoFabrik for making this incredibly easy)
OSM is indispensable for map projects (e.g. is powers the popular offline maps app Maps.me). Because apart from OSM, only huge corporations like Google or Microsoft have this kind of map data (please consider contributing).
Under the hood OSM is just an XML structure which contains edges (streets, walkways, subway lines, country borders, etc.) and nodes (traffic lights, trees, ATMs, benches, etc.). There is a long long list to tell people the correct way of tagging in order to keep things consistent across the entire globe.
Getting data for the ground was easy, but the challenge lying ahead was to merge the data of sky and ground.
1.3. Flights + Streets
If you want to get from A to B, you might open Google Maps, enter your destination, then magic happens and: You know how to get there.
The difference: We wanted to get to our destination multimodally – by combining flying and driving. Not even Google Maps currently supports this. So we downloaded data for the entire globe and got going.
Routing
What Google maps (or any other similar service) is doing when you search for directions is routing. Routing is part of what people commonly call navigation. There are many open source routing solutions that are based on OSM. We picked GraphHopper for Roads to Rome and found it quite good to work with so we sticked with it. (Also their team was always incredibly helpful when we had questions)
Flights = Superhighways
GraphHopper doesn’t support flight routing (also no other OSM routing engine does), so we tricked the system. We added our flight corridors into the system as super fast highways. If the car sees this hyper-Autobahn, why shouldn’t it use it.
In theory this is easy, but it turns out you have to know exactly how the OSM format works:
- What are OSM IDs? (Numbers)
- Which IDs can I use? (Everything above 4294967296)
- Are IDs unique? (Kind of)
- How do I generate the file? (Nobody will tell you)
- Is the file’s content sorted in a certain way? (Yes)
- Can you introduce my own type of streets? (Yes, but better tell Graphhopper)
- How fast can cars go? (What are your settings?)
- Can cars exit the world on the left and reenter on the right? (No, better think of a workaround)
- ...
A lot of this is documented, but many other things you only learn from frustrating trial and error. But eventually it did work and we could load the data into Graphhopper (without streets as a first test):
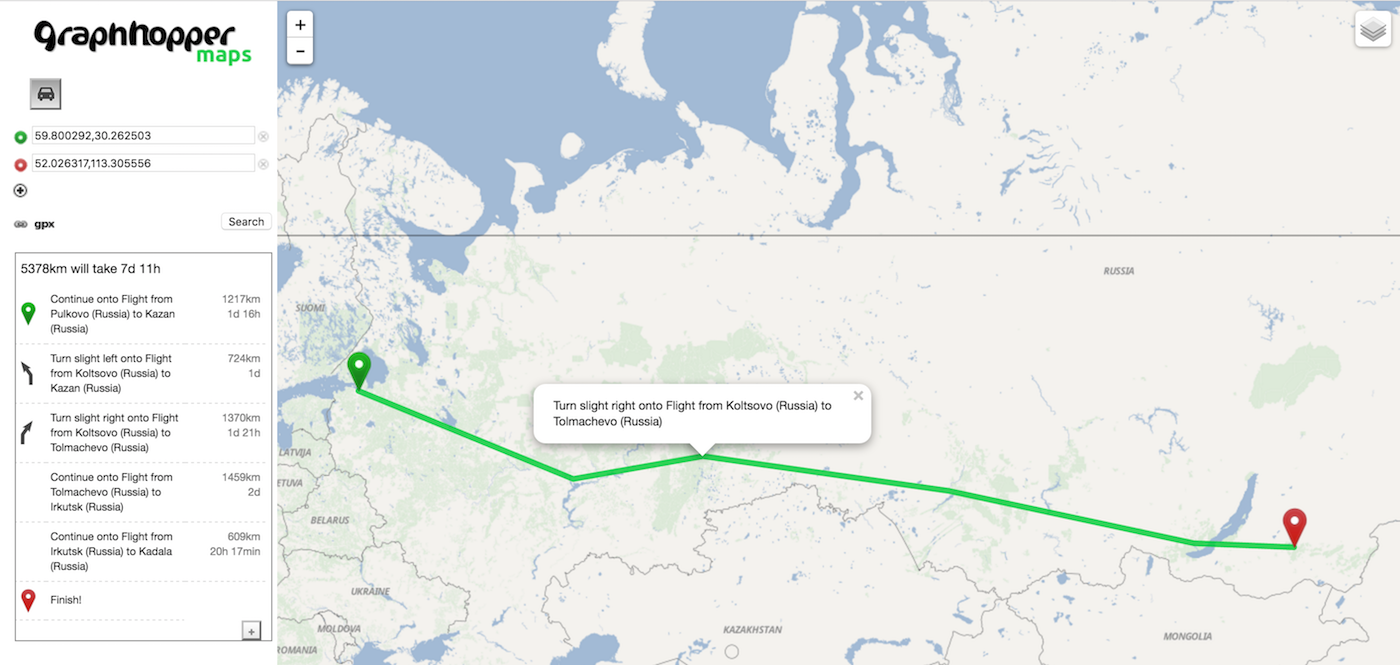
graphhopper - behind the scenes
What you can see is that the detailed trajectory is not necessary to find the way from A to B, so we actually remove it which makes everything faster. We just need the connection data.
A major success to us, because this proves the feasibility of the project.
Bridges to the sky
Unfortunately flights start and leave from airports, not streets. We had to connect the two, basically intersecting a flight path with a road connection. We did this by searching for the closest (publicly accessible) street from every airport on earth.
We used a tool called OverpassTurbo, which lets you search within the OSM dataset (streets/water fountains/kindergartens/hospitals/… everything).
That’s by the way how we found the most remote airports (airports that have no streets within many kilometers).
So we created our flight-OSM-file (with airport-street-connections), merged it with our local roads-OSM-file (using tool called osmconvert) and had a look:
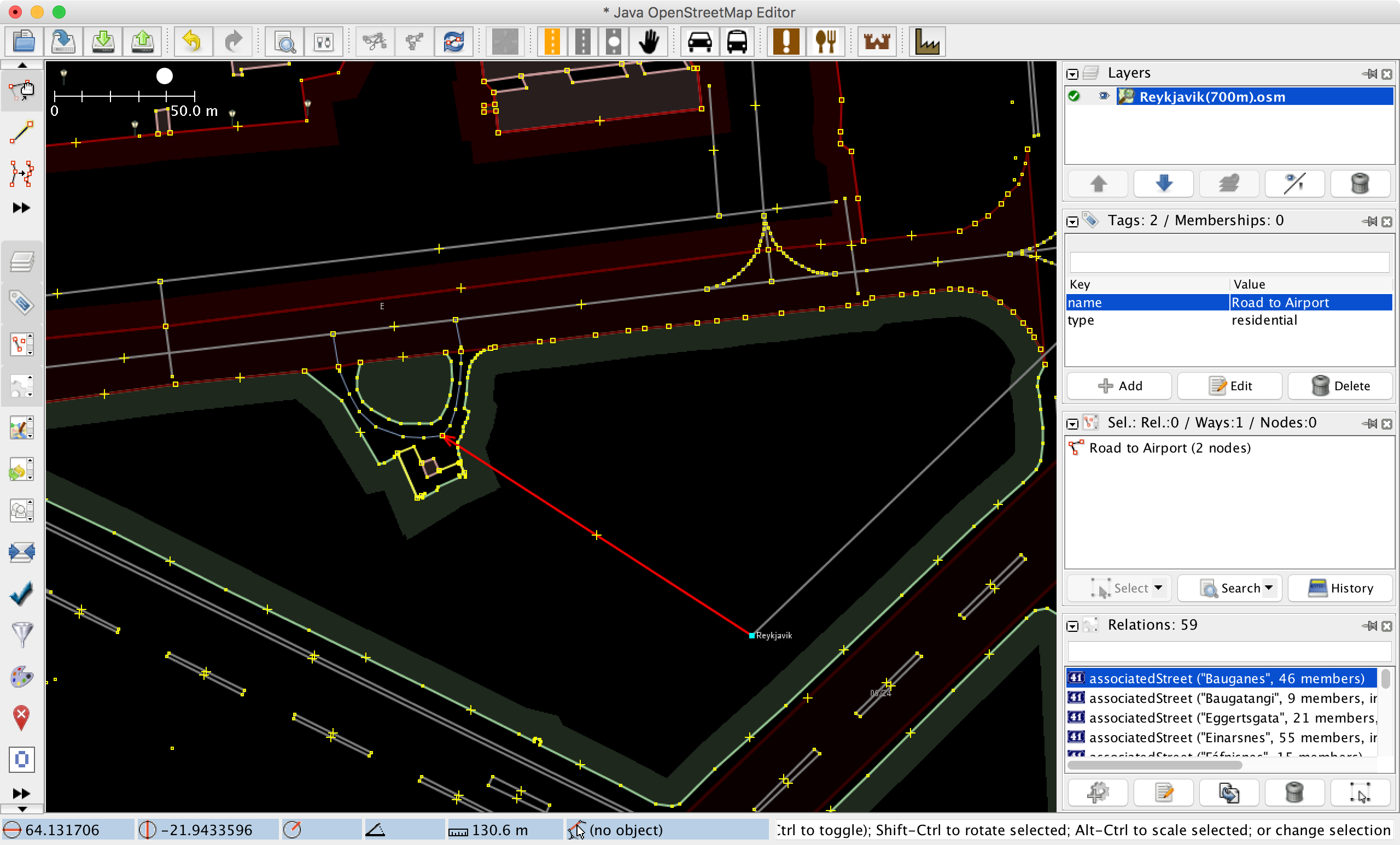
OpenStreetMap JOSM
is a handy OSM editor which we used for inspecting our generate OSM-files. Here you can see the link between a road and a flight
Surprisingly – after a long period of struggle – everything worked. Now we just had to use GraphHopper and our data to find how people would travel.
Note: We often thought that the next step was “just” XYZ, but it rarely was that simple. Having the proof of concept half way into the project can be unsettling from time to time.
2. People’s journeys
Thankfully we solved this problem already with Roads to Rome (thanks to Benedikt Groß and Philipp Schmitt):
If you want to know every possible way to Rome (or any other point on earth for that matter), you “just” have to define your starting points on earth. So what we did is create evenly spread points on every part of land on earth and let GraphHopper generate a route to Rome starting from these points.
Where do you start?
...when you want to know all journeys to get to Rome?
For Flights to Rome, we had to make some changes (i.e. to get analytics on how often which flights were taken or re-adding details to flight corridors), but the approach (and code) was essentially the same.
Once you start the process, you wait for 4 – 5 hours for it to finish and pray to your favourite god, that it doesn’t fail (it failed a lot). → Personal Learnings: Working with big data
If it did not fail however, you get this:
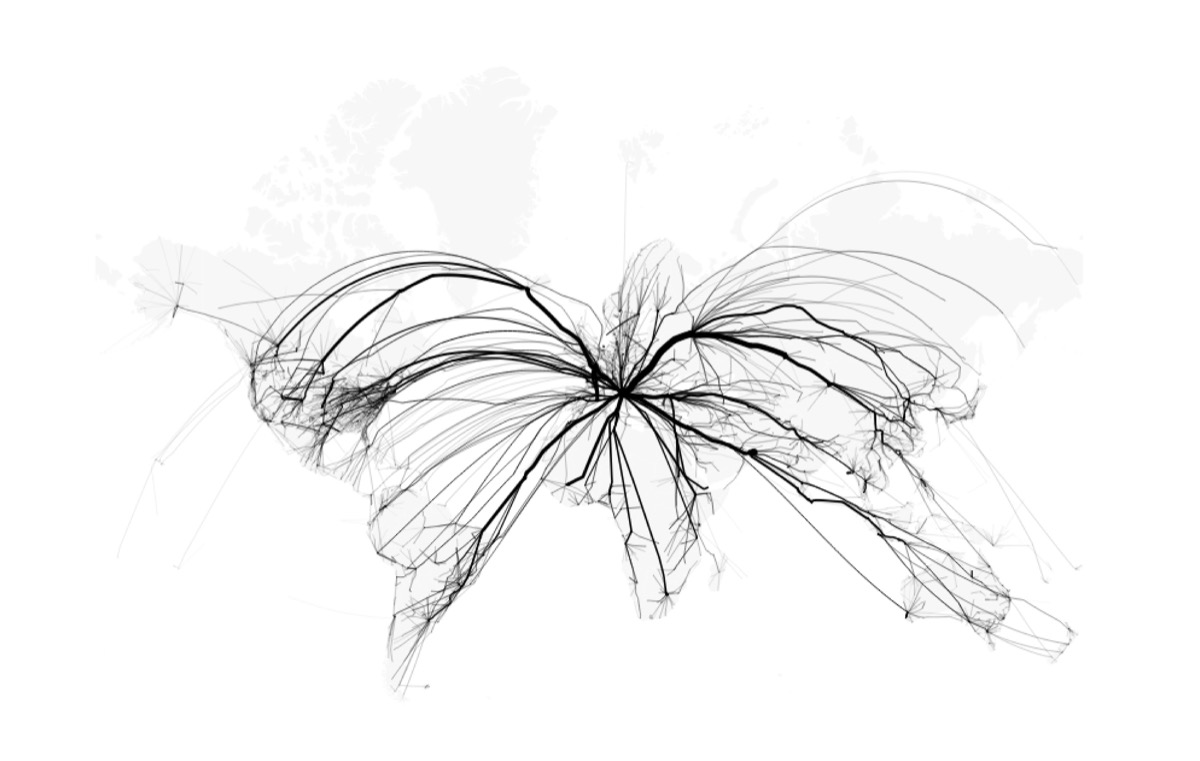
Going up ...but not really 3D yet.
The map appears to be viewed at from an angle with the planes rising into the sky and coming back down, but [again] this is just about how maps are created.
This part of the project felt like a lottery – in all the good and the bad ways. You buy your lottery ticket (hit enter on your keyboard), then you wait for next week’s numbers (the computer to do all calculations) and hope you win the jackpot (output is not garbage).
I never won the lottery, but when I saw the output above, I got an idea of what winning it must feel like.
3. The Artwork
Once all the technical parts were sorted out, we could focus on how to present the generated data.
3.1 Preparing for takeoff (three reads)
What we loved about Roads to Rome was, that you could see countries even without a prominent map in the background. We wanted to keep that principle, but now with flying and driving combined (Flights > Roads > Map).
In case you are wondering why the following images are Germany only:
- It takes many hours to calculate the image for the entire globe, so for testing and iterating we used a small dataset like Germany
- Importing a lot of data makes the tools slow (you wait for up to a few minutes whenever you drag the viewport)
- I could generate the images for Germany on my laptop – the global ones were created on a bigger machine
Approach 1: 2D
We opened the data we exported, gave flights and rides different colors and looked at it:
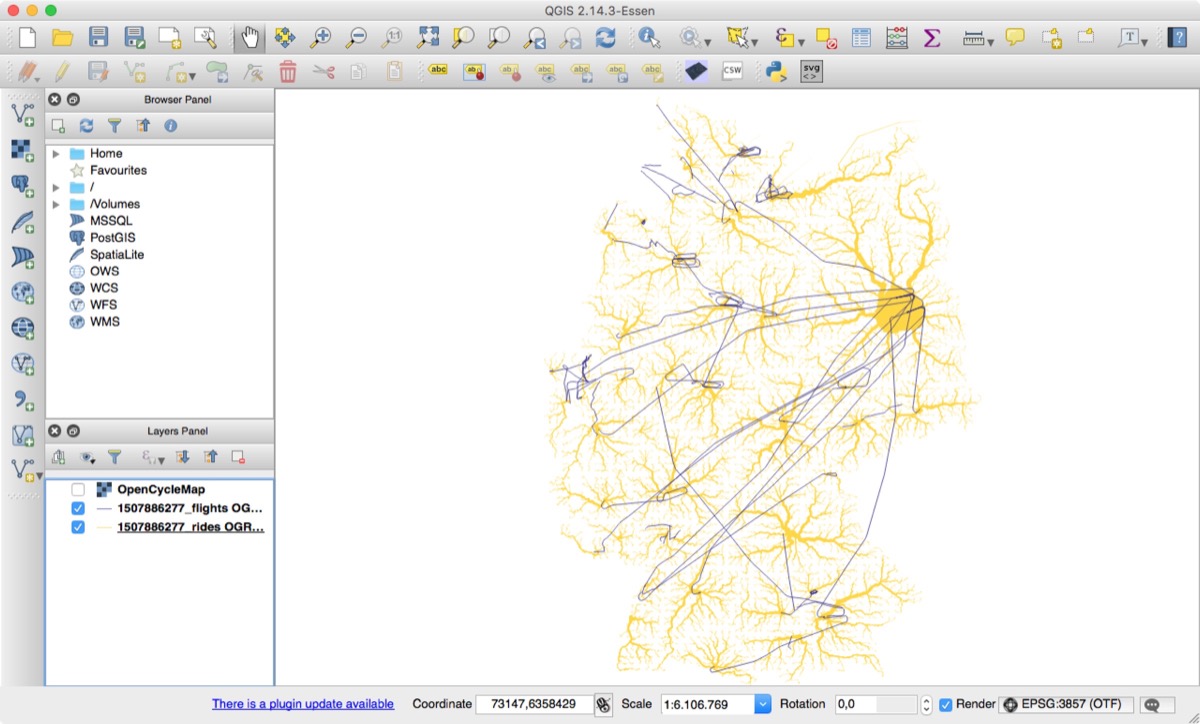
3-2-1- Lift Off! Are we 3d yet? nahh.
Germany and its domestic flights as they’d look from space.
… it wasn’t how we expected or hoped it to be. It didn’t look very glorious, even if you’d use nicer colors. We thought the issue was that the flights didn’t really look like flights due to the lack the third dimension.
Approach 2: Faux 3D
A simple approach to 3D is cheating (faux 3D). Like those old computer games where you see the front of the house and the roof simultaneously. They are 2D, but it appears that you look at the world from an angle. We used the same approach, by drawing the flight lines more north depending on how high the plane was flying at a given point:
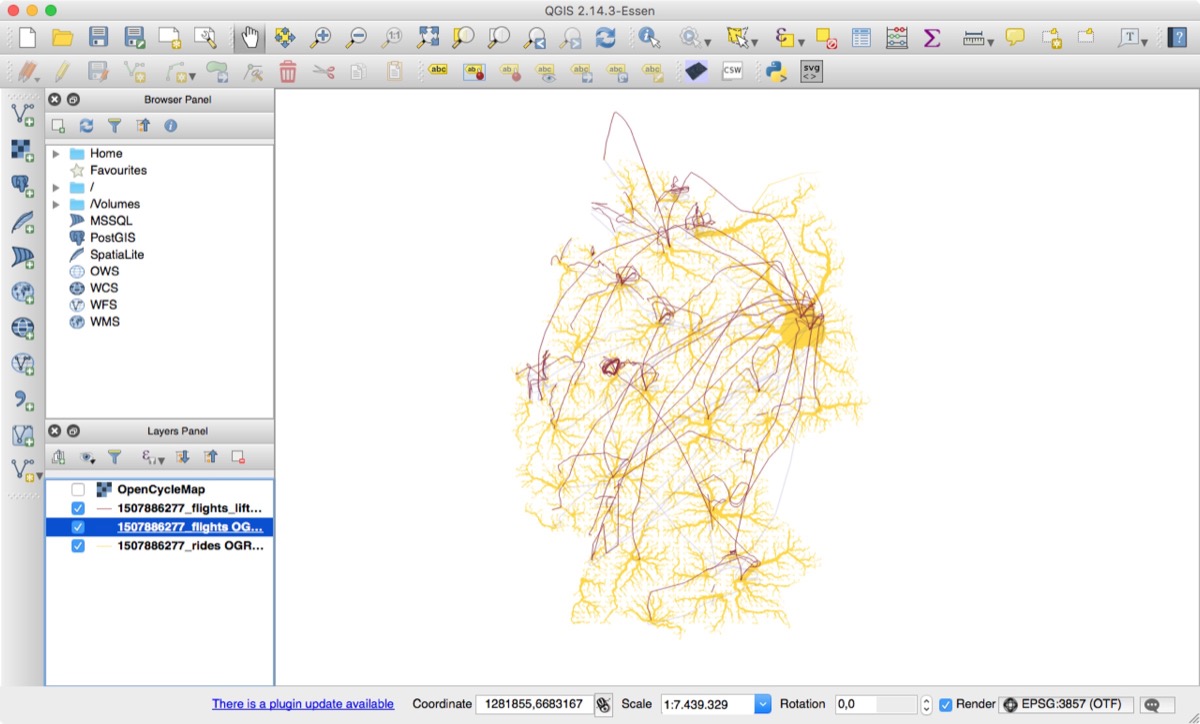
3-2-1- Lift Off! Next Faux 3D Style.
The same image, but with the flights lifted and shadows added.
Way better than before, but it is still difficult to discern between different flight layers.
At this stage, we knew we had to go real 3D. So we set on a search and found artist Herwig Scherabon – one of not many 3D artists that know how to create insights through beautiful imagery.
3.2 Up in the air (finding a style)
By finding Herwig, we also found our new problem: how to get geo data into our 3D tool of choice (Cinema4D).
Geo → CAD
We had to convert from a geo file to a 3D file. This issue is not common, because geographers rarely have to deal with the 3rd dimension – most geo tools don’t even support 3D.
Geo and CAD files are related – they all deal with coordinates in space, but the difference is:
- Cinema4D can’t open geojson (the obvious issue)
- Geo files use polar coordinates and 3D tools cartesian coordinates (explanation)
We ended up using converting to DXF and specifically polylines. This meant that we had lines in 3D space, but without any thickness which should show how often a route was taken.
Grasshopper
We found that Grasshopper 3D (no this is not the same as the routing tool GraphHopper) – a plugin for Rhinoceros – is a very convenient way to use data to generate 3D geometry. It lets you interact with the input and modify parameters.
Unfortunately DXF is a very simple file format which meant that we couldn’t pass any additional information directly, so we added the number of flights as the object ID to each geometry. A little hack essentially, because this is not what you use object IDs for.
But it worked and we could generate the 3D tubes. After a few tests we found that a rectangular profile with a light fillet is a good solution for us.
The node-based Grasshopper programming interface.
The exponential thickness scaling for our flights https://github.com/d3/d3-scale#power-scales
Through a grasshopper node specifically made to inject python code we managed to get a great fall-off for the tube thickness. The thickness scale is an exponential one based on the d3.scale.pow[] function, see the settings in the code above.
After we generated the geometries in Grasshopper we could easily export it as OBJ into Cinema 4D.
Since the coordinate systems of the flight paths, the road image and the basemap had to have the same zero point, we built rectangles where the images would need to go in a later step. Those rectangles were placeholders for stitching together images, vector files and 3D geometry coming from four different tools. The whole scene in Rhinoceros and Grasshopper had to be the exact same one as in Cinema 4D.
The Basemap
The inspiration for the base map comes from old hiking maps from the 50ies where they used sprayed dots to create shading. We intentionally wanted to stick to a bit of a retro look for the basemap
#Inspiration!
An old hiking map from the 50ies
The data for our basemap is from Natural Earth Data (great open data source for large scale visualisation). To get the effect we wanted, we used cross-blended hypsometric tints for coloring.
We also used a bathymetry (lines showing similar depth of water) for adding an interesting texture to the vast areas of water. The roads were displayed as raster graphics on top of the basemap. It was very difficult to mediate between the legibility of the roads and the basemap. The priority however, was to show the movement from roads to airplanes, since this was the essence of our storytelling. We used QGIS to extract vector graphics and image data from Natural Earth Data into textures for Cinema 4D.
Styling
The overall look and feel of the map is supposed to be friendly and accessible, but with a bit of an edge to it. We decided that light colors are the most suitable for our purpose. However we wanted the most important part (the flight paths) stick out instantly and therefore colored them with a saturated red. Our previous versions were a bit more abstract and minimalist than the final result. Still it was important to us to be accessible to a larger audience. That is why we started to experiment with old map styles like dotted hillshade patterns and classic coloring for landscapes and a more natural look.
Herwig bringing in his 3D styles.
Many iterations later we to this point...
Geo → JPG
When we tried to import our newly converted data into Cinema4D, it failed. The amount of streets was just too much for Cinema4D to handle.
We ended up exporting the street image using Tilemill (which handles large amounts of data and can export beautiful maps even for large prints) and only importing the flights in 3D.
The baselayer of streets is an interesting image by itself, because it essentially shows the closest airport to any given location on earth:

People on their way to the airport
...excited about visiting Rome.
3.3 Arriving at our destination (the final image)
After recombining 3D flights and 2D rides (and adding some style iterations and a basemap) we end up where this article started – with Flights to Rome:
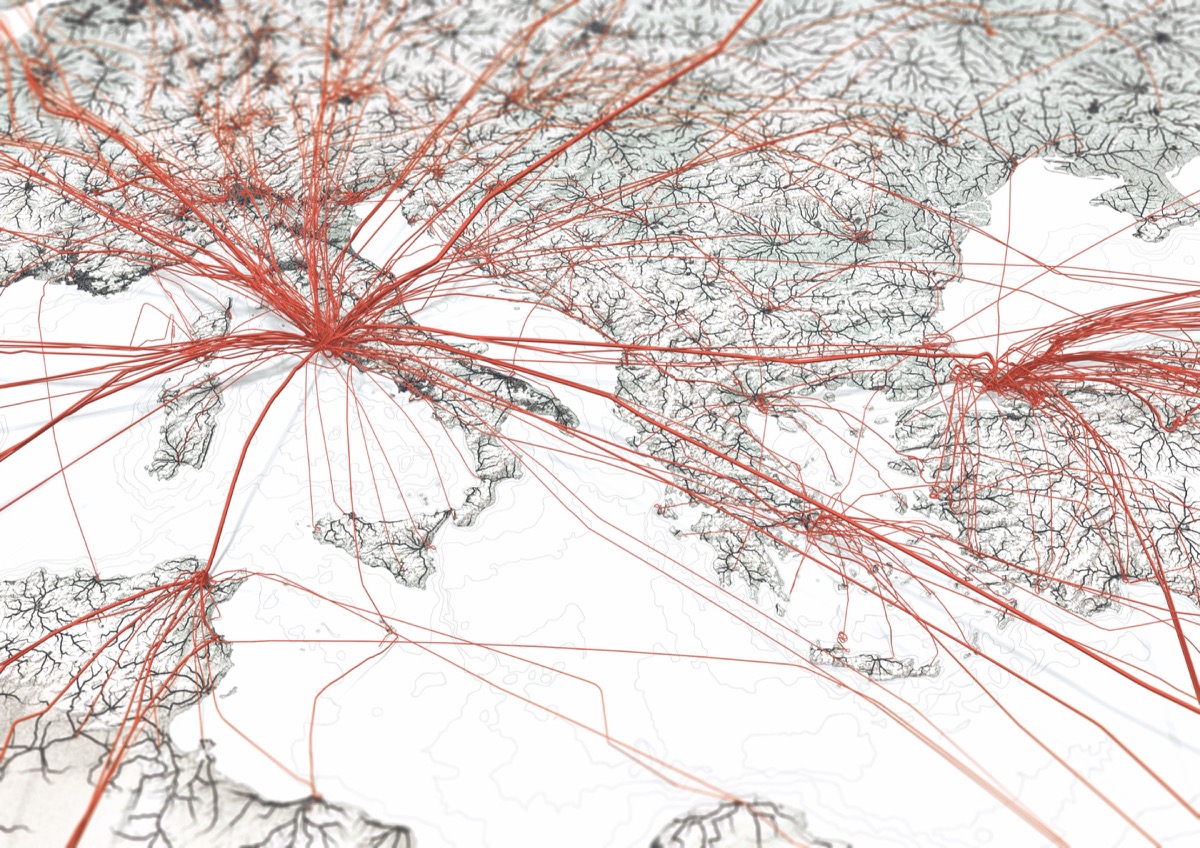
Ladies and Gentlemen,
...we are now in our final descent to Rome.
Summary
Making Flights to Rome was a wild ride. It took us across an entire landscape of what digital geography offers – large datasets, map projections, OSM, routing, 3D, …
When we started off, we didn’t know how many small and large steps we had to take to make the project happen, like most of the time when starting a lab project.
We are happy that we could complete it, because at times it seemed impossible for such a small team. There were many things we learned during the project, which we’d be happy to pass onto you – so please read also the last bits that follow.
♥ from moovel lab
Personal Learnings
If you still havent had enough, here are some of my personal leanings from this project, I'd like to share.
Border between coding designer and developer
Like drawing, writing (hello enduring reader) or speaking, code is also a form of expression. And it is the most versatile way humans have come up so far to precisely express a certain behaviour. There are tools that abstract code – e.g. for prototyping (like Principle) or dataviz (like Tableau) – but at the cost of versatility. At some point you will feel limited by what the tool offers and you will search for more freedom … which you will find in coding.
If you judge a designer by his skills to express an idea, programming is as necessary as sketching, but the important point is: You don’t have to program as good as a programmer, draw as good as an illustrator or write as good as a writer. You just have to be good enough to express your thoughts.
When I worked on Flights to Rome I basically only coded for weeks without opening any design tool. I still am a designer because the point of writing code was to express the idea of what Flights to Rome should be. The times I crossed that border between expression and pure development were the moments where work tedious and painful.
Debugging as inspiration
Sometimes the tools you create to inspect your data can become inspiration by itself. For example the altitude plots were our solution to check the reliability of altitude data. In the end we thought that those plots are worthy to be shown on their own.
Working with data ≠ working with large data
The difficulty about working with large datasets is the inability to inspect anything manually. It is just too ... well ... large. So what you do is:
Clean
“Garbage in, garbage out” – if you don’t know what you are dealing with, how can you be prepared for what comes? (I.e. if you draw values for a chart, but some values say “undefined” instead of numbers your program likely will crash)
So go through your data, get rid of (or convert) everything that is unexpected and continue working with this cleaned dataset.
Stream
Small data can be loaded into your computer all at once. The limiting factor is RAM which (today) rarely is a problem. But large datasets can be many Gigabytes or even Terabytes in size. So instead, you read the data in chunks (e.g. every line of a csv). This means you can never work with all data at once, but at least you can work with it.
Let inspect
Even if you data has no flaws, you still don’t know what is hidden in it. But because it is too large you cannot just open a file and read through it. You have to write programs which do that for you. (There is an article about a video game with an entirely procedurally generated universe that explains this issue well)
Wait
Computers are incredibly fast today but processing still takes time. And the more you process, the longer it takes. With this project we often had to wait many hours to inspect your result. You can imagine how much you get done if you can only do a few iterations each day – at least you get to have many tea breaks.
Automate
Let’s say you have ten separate processes, that each take half hour. It is incredibly tedious to wait for one process in order to start the next (with the output of the previous). The solution of course is automating, because otherwise you will only work effectively for like twenty minutes a day. Also, you will iterate less often if the process itself is too painful.
Modularize, modularize, modularize
In a complex system errors can happen anywhere. The only way (I know of) to fix those, is to make sure that the individual parts of the system work (→ test-driven development). That way, you know that the communication between them is the issue (or the system itself).
A great example is the library turf.js (which we also heavily used for Flights to Rome).
Code as a sketch
If you create something that you are not certain will work, you make a rough version first. This is the same with code as it is with pen and paper. It feels painful at first, but at some point you will accept that code is just your way of sketching with data.
And like with sketching you only add details if necessary. Why spend time polishing your code if it might only run once after all? The few times I optimized code was to bring down the runtime from weeks to hours.
Estimating the unknown
Sometimes Benedikt asked my how long something would take. My answer would be “It could be 2 minutes or 2 months, but I will know in 2 minutes if it might take 2 months”.
I’ve never worked in research, but this must be what it feels like – the feeling that you are incredibly close to something but once you try to touch it, it suddenly is miles away.
Many thanks for reading all the way to the bottom. If you still have questions, please reach out to me or someone from the lab.